Forecasting with Exogenous Regressors¶
This notebook provides examples of the accepted data structures for passing the expected value of exogenous variables when these are included in the mean. For example, consider an AR(1) with 2 exogenous variables. The mean dynamics are
The \(h\)-step forecast, \(E_{T}[Y_{t+h}]\), depends on the conditional expectation of \(X_{0,T+h}\) and \(X_{1,T+h}\),
where \(E_{T}[Y_{T+h-1}]\) has been recursively computed.
In order to construct forecasts up to some horizon \(h\), it is necessary to pass \(2\times h\) values (\(h\) for each series). If using the features of forecast that allow many forecast to be specified, it necessary to supply \(n \times 2 \times h\) values.
There are two general purpose data structures that can be used for any number of exogenous variables and any number steps ahead:
dict- The values can be pass using adictwhere the keys are the variable names and the values are 2-dimensional arrays. This is the most natural generalization of a pandasDataFrameto 3-dimensions.array- The vales can alternatively be passed as a 3-d NumPyarraywhere dimension 0 tracks the regressor index, dimension 1 is the time period and dimension 2 is the horizon.
When a model contains a single exogenous regressor it is possible to use a 2-d array or DataFrame where dim0 tracks the time period where the forecast is generated and dimension 1 tracks the horizon.
In the special case where a model contains a single regressor and the horizon is 1, then a 1-d array or pandas Series can be used.
[1]:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn
seaborn.set_style("darkgrid")
plt.rc("figure", figsize=(16, 6))
plt.rc("savefig", dpi=90)
plt.rc("font", family="sans-serif")
plt.rc("font", size=14)
Simulating data¶
Two \(X\) variables are simulated and are assumed to follow independent AR(1) processes. The data is then assumed to follow an ARX(1) with 2 exogenous regressors and GARCH(1,1) errors.
[2]:
from arch.univariate import ARX, GARCH, ZeroMean, arch_model
burn = 250
x_mod = ARX(None, lags=1)
x0 = x_mod.simulate([1, 0.8, 1], nobs=1000 + burn).data
x1 = x_mod.simulate([2.5, 0.5, 1], nobs=1000 + burn).data
resid_mod = ZeroMean(volatility=GARCH())
resids = resid_mod.simulate([0.1, 0.1, 0.8], nobs=1000 + burn).data
phi1 = 0.7
phi0 = 3
y = 10 + resids.copy()
for i in range(1, y.shape[0]):
y[i] = phi0 + phi1 * y[i - 1] + 2 * x0[i] - 2 * x1[i] + resids[i]
x0 = x0.iloc[-1000:]
x1 = x1.iloc[-1000:]
y = y.iloc[-1000:]
y.index = x0.index = x1.index = np.arange(1000)
Plotting the data¶
[3]:
ax = pd.DataFrame({"ARX": y}).plot(legend=False)
ax.legend(frameon=False)
_ = ax.set_xlim(0, 999)
Forecasting the X values¶
The forecasts of \(Y\) depend on forecasts of \(X_0\) and \(X_1\). Both of these follow simple AR(1), and so we can construct the forecasts for all time horizons. Note that the value in position [i,j] is the time-i forecast for horizon j+1.
[4]:
x0_oos = np.empty((1000, 10))
x1_oos = np.empty((1000, 10))
for i in range(10):
if i == 0:
last = x0
else:
last = x0_oos[:, i - 1]
x0_oos[:, i] = 1 + 0.8 * last
if i == 0:
last = x1
else:
last = x1_oos[:, i - 1]
x1_oos[:, i] = 2.5 + 0.5 * last
x1_oos[-1]
[4]:
array([4.11430984, 4.55715492, 4.77857746, 4.88928873, 4.94464437,
4.97232218, 4.98616109, 4.99308055, 4.99654027, 4.99827014])
Fitting the model¶
Next, the model is fit. The parameters are precisely estimated.
[5]:
exog = pd.DataFrame({"x0": x0, "x1": x1})
mod = arch_model(y, x=exog, mean="ARX", lags=1)
res = mod.fit(disp="off")
print(res.summary())
AR-X - GARCH Model Results
==============================================================================
Dep. Variable: data R-squared: 0.990
Mean Model: AR-X Adj. R-squared: 0.990
Vol Model: GARCH Log-Likelihood: -1386.43
Distribution: Normal AIC: 2786.86
Method: Maximum Likelihood BIC: 2821.20
No. Observations: 999
Date: Tue, Nov 05 2024 Df Residuals: 995
Time: 09:03:35 Df Model: 4
Mean Model
========================================================================
coef std err t P>|t| 95.0% Conf. Int.
------------------------------------------------------------------------
Const 3.0144 0.163 18.548 8.430e-77 [ 2.696, 3.333]
data[1] 0.7015 3.946e-03 177.778 0.000 [ 0.694, 0.709]
x0 2.0049 2.417e-02 82.961 0.000 [ 1.958, 2.052]
x1 -2.0067 2.606e-02 -77.006 0.000 [ -2.058, -1.956]
Volatility Model
==========================================================================
coef std err t P>|t| 95.0% Conf. Int.
--------------------------------------------------------------------------
omega 0.2428 0.106 2.296 2.165e-02 [3.557e-02, 0.450]
alpha[1] 0.1427 3.842e-02 3.713 2.047e-04 [6.736e-02, 0.218]
beta[1] 0.6075 0.128 4.732 2.224e-06 [ 0.356, 0.859]
==========================================================================
Covariance estimator: robust
Using a dict¶
The first approach uses a dict to pass the two variables. The key consideration here is the the keys of the dictionary must exactly match the variable names (x0 and x1 here). The dictionary here contains only the final row of the forecast values since forecast will only make forecasts beginning from the final in-sample observation by default.
Using DataFrame¶
While these examples make use of NumPy arrays, these can be DataFrames. This allows the index to be used to track the forecast origination point, which can be a helpful device.
[6]:
exog_fcast = {"x0": x0_oos[-1:], "x1": x1_oos[-1:]}
forecasts = res.forecast(horizon=10, x=exog_fcast)
forecasts.mean.T.plot()
[6]:
<Axes: >
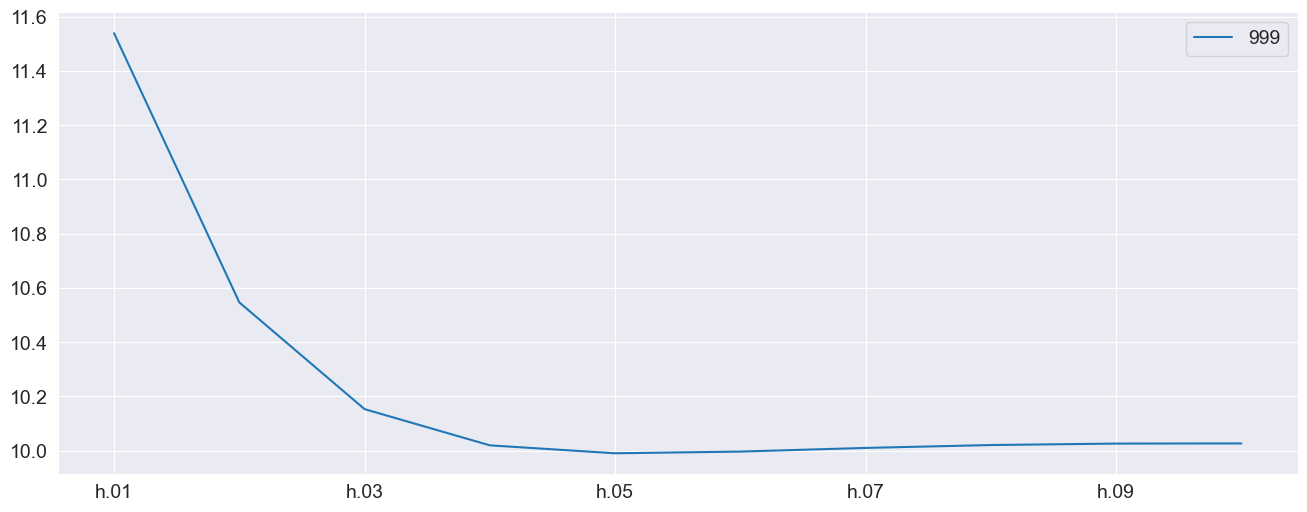
Using an array¶
An array can alternatively be used. This frees the restriction on matching the variable names although the order must match instead. The forecast values are 2 (variables) by 1 (forecast) by 10 (horizon).
[7]:
exog_fcast = np.array([x0_oos[-1:], x1_oos[-1:]])
print(f"The shape is {exog_fcast.shape}")
array_forecasts = res.forecast(horizon=10, x=exog_fcast)
print(array_forecasts.mean - forecasts.mean)
The shape is (2, 1, 10)
h.01 h.02 h.03 h.04 h.05 h.06 h.07 h.08 h.09 h.10
999 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
Producing multiple forecasts¶
forecast can produce multiple forecasts using the same fit model. Here the model is fit to the first 500 observations and then forecasting for the remaining values are produced. It must be the case that the x values passed for forecast have the same number of rows as the table of forecasts produced.
[8]:
res = mod.fit(disp="off", last_obs=500)
exog_fcast = {"x0": x0_oos[-500:], "x1": x1_oos[-500:]}
multi_forecasts = res.forecast(start=500, horizon=10, x=exog_fcast)
multi_forecasts.mean.tail(10)
[8]:
| h.01 | h.02 | h.03 | h.04 | h.05 | h.06 | h.07 | h.08 | h.09 | h.10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 990 | 2.540145 | 3.881133 | 5.061650 | 6.053388 | 6.865819 | 7.522019 | 8.047798 | 8.467201 | 8.800961 | 9.066272 |
| 991 | 0.215980 | 1.032457 | 2.006769 | 3.022749 | 4.007480 | 4.919173 | 5.737291 | 6.455111 | 7.074418 | 7.601849 |
| 992 | -1.349766 | -0.361748 | 0.851086 | 2.099585 | 3.284864 | 4.359797 | 5.306750 | 6.124531 | 6.820676 | 7.406900 |
| 993 | -4.817724 | -3.512921 | -1.784485 | -0.014055 | 1.628199 | 3.077623 | 4.320987 | 5.368910 | 6.241861 | 6.963181 |
| 994 | -1.560535 | 0.849447 | 2.911301 | 4.577012 | 5.881864 | 6.886564 | 7.652839 | 8.234472 | 8.675148 | 9.009059 |
| 995 | -1.787821 | -0.481965 | 0.926577 | 2.285772 | 3.524951 | 4.617392 | 5.559692 | 6.360283 | 7.033020 | 7.593623 |
| 996 | 0.682806 | 1.967093 | 3.248706 | 4.414385 | 5.426521 | 6.282666 | 6.995494 | 7.583028 | 8.064035 | 8.455986 |
| 997 | 5.856533 | 6.643855 | 7.101694 | 7.441397 | 7.741882 | 8.026316 | 8.296863 | 8.549624 | 8.780471 | 8.986870 |
| 998 | 5.703605 | 6.735543 | 7.451093 | 7.978391 | 8.384628 | 8.706740 | 8.966470 | 9.177733 | 9.350221 | 9.491178 |
| 999 | 9.600716 | 9.597845 | 9.364377 | 9.144876 | 9.011465 | 8.967210 | 8.992284 | 9.063245 | 9.160068 | 9.267872 |
The plot of the final 5 forecast paths shows the the mean reversion of the process.
[9]:
_ = multi_forecasts.mean.tail().T.plot()
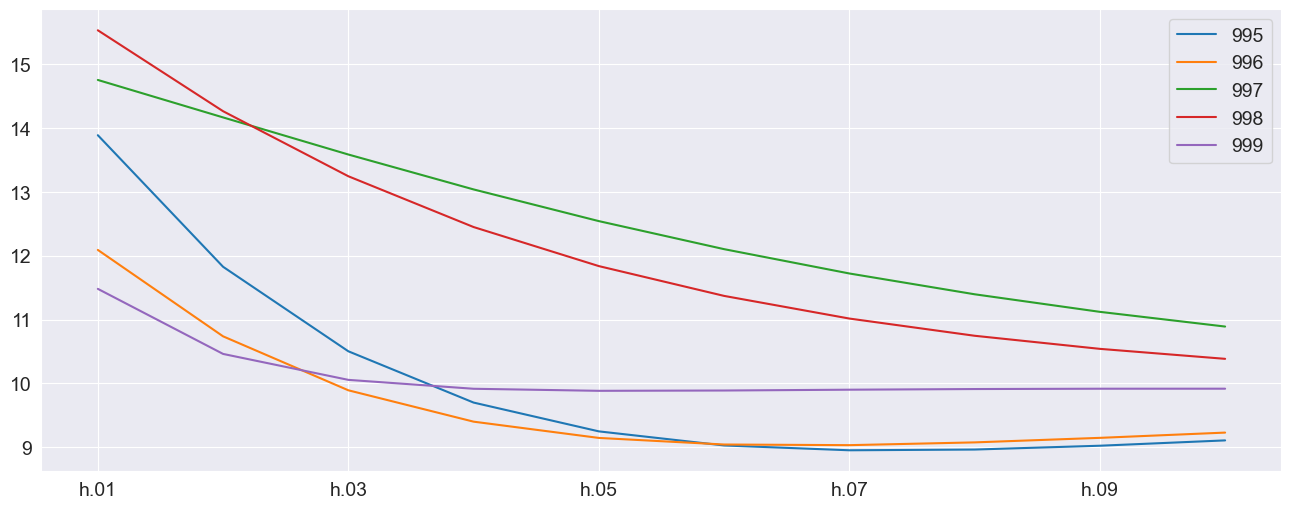
The previous example made use of dictionaries where each of the values was a 500 (number of forecasts) by 10 (horizon) array. The alternative format can be used where x is a 3-d array with shape 2 (variables) by 500 (forecasts) by 10 (horizon).
[10]:
exog_fcast = np.array([x0_oos[-500:], x1_oos[-500:]])
print(exog_fcast.shape)
array_multi_forecasts = res.forecast(start=500, horizon=10, x=exog_fcast)
np.max(np.abs(array_multi_forecasts.mean - multi_forecasts.mean))
(2, 500, 10)
[10]:
np.float64(0.0)
x input array sizes¶
While the natural shape of the x data is the number of forecasts, it is also possible to pass an x that has the same shape as the y used to construct the model. The may simplify tracking the origin points of the forecast. Values are are not needed are ignored. In this example, the out-of-sample values are 2 by 1000 (original number of observations) by 10. Only the final 500 are used.
WARNING
Other sizes are not allowed. The size of the out-of-sample data must either match the original data size or the number of forecasts.
[11]:
exog_fcast = np.array([x0_oos, x1_oos])
print(exog_fcast.shape)
array_multi_forecasts = res.forecast(start=500, horizon=10, x=exog_fcast)
np.max(np.abs(array_multi_forecasts.mean - multi_forecasts.mean))
(2, 1000, 10)
[11]:
np.float64(0.0)
Special Cases with a single x variable¶
When a model consists of a single exogenous regressor, then x can be a 1-d or 2-d array (or Series or DataFrame).
[12]:
mod = arch_model(y, x=exog.iloc[:, :1], mean="ARX", lags=1)
res = mod.fit(disp="off")
print(res.summary())
AR-X - GARCH Model Results
==============================================================================
Dep. Variable: data R-squared: 0.935
Mean Model: AR-X Adj. R-squared: 0.935
Vol Model: GARCH Log-Likelihood: -2353.18
Distribution: Normal AIC: 4718.35
Method: Maximum Likelihood BIC: 4747.79
No. Observations: 999
Date: Tue, Nov 05 2024 Df Residuals: 996
Time: 09:03:36 Df Model: 3
Mean Model
========================================================================
coef std err t P>|t| 95.0% Conf. Int.
------------------------------------------------------------------------
Const -6.6246 0.288 -23.013 3.448e-117 [ -7.189, -6.060]
data[1] 0.7754 1.114e-02 69.595 0.000 [ 0.754, 0.797]
x0 1.7834 6.496e-02 27.452 6.638e-166 [ 1.656, 1.911]
Volatility Model
===========================================================================
coef std err t P>|t| 95.0% Conf. Int.
---------------------------------------------------------------------------
omega 5.6542 2.905 1.947 5.159e-02 [-3.904e-02, 11.347]
alpha[1] 0.1453 7.887e-02 1.843 6.540e-02 [-9.261e-03, 0.300]
beta[1] 0.0000 0.492 0.000 1.000 [ -0.964, 0.964]
===========================================================================
Covariance estimator: robust
These two examples show that both formats can be used.
[13]:
forecast_1d = res.forecast(horizon=10, x=x0_oos[-1])
forecast_2d = res.forecast(horizon=10, x=x0_oos[-1:])
print(forecast_1d.mean - forecast_2d.mean)
## Simulation-forecasting
mod = arch_model(y, x=exog, mean="ARX", lags=1, power=1.0)
res = mod.fit(disp="off")
h.01 h.02 h.03 h.04 h.05 h.06 h.07 h.08 h.09 h.10
999 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
Simulation¶
forecast supports simulating paths. When forecasting a model with exogenous variables, the same value is used to in all mean paths. If you wish to also simulate the paths of the x variables, these need to generated and then passed inside a loop.
Static out-of-sample x¶
This first example shows that variance of the paths when the same x values are used in the forecast. There is a sense the out-of-sample x are treated as deterministic.
[14]:
x = {"x0": x0_oos[-1], "x1": x1_oos[-1]}
sim_fixedx = res.forecast(horizon=10, x=x, method="simulation", simulations=100)
sim_fixedx.simulations.values.std(1)
[14]:
array([[1.0839085 , 1.35056703, 1.32247756, 1.37376702, 1.42766883,
1.26413038, 1.40082683, 1.4457671 , 1.60341732, 1.52885261]])
Simulating the out-of-sample x¶
This example simulates distinct paths for the two exogenous variables and then simulates a single path. This is then repeated 100 times. We see that variance is much higher when we account for variation in the x data.
[15]:
from numpy.random import RandomState
def sim_ar1(params: np.ndarray, initial: float, horizon: int, rng: RandomState):
out = np.zeros(horizon)
shocks = rng.standard_normal(horizon)
out[0] = params[0] + params[1] * initial + shocks[0]
for i in range(1, horizon):
out[i] = params[0] + params[1] * out[i - 1] + shocks[i]
return out
simulations = []
rng = RandomState(20210301)
for i in range(100):
x0_sim = sim_ar1(np.array([1, 0.8]), x0.iloc[-1], 10, rng)
x1_sim = sim_ar1(np.array([2.5, 0.5]), x1.iloc[-1], 10, rng)
x = {"x0": x0_sim, "x1": x1_sim}
fcast = res.forecast(horizon=10, x=x, method="simulation", simulations=1)
simulations.append(fcast.simulations.values)
Finally the standard deviation is quite a bit larger. This is a most accurate value fo the long-run variance of the forecast residuals which should account for dynamics in the model and any exogenous regressors.
[16]:
joined = np.concatenate(simulations, 1)
joined.std(1)
[16]:
array([[3.17217908, 5.02189248, 6.55403744, 7.76849119, 8.5381655 ,
8.69810759, 8.60407729, 8.82725838, 8.98471687, 9.17739333]])
Conditional Mean Alignment vs. Forecast Alignment¶
When fitting a model with exogenous variables, the data are aligned so that the values in x[j] are used to compute the conditional mean of y[j]. For example, in the case of an AR(1)-X, the model is
We can recover the conditional mean by subtracting the residuals from the original data. When we do this we see that the conditional mean of observation 0 is missing since we need one lag of \(Y\) to fit the model.
[17]:
mod = arch_model(y, x=exog, mean="ARX", lags=1)
res = mod.fit(disp="off")
y - res.resid
[17]:
0 NaN
1 15.403422
2 9.315820
3 9.488624
4 8.559554
...
995 -3.690107
996 -1.863553
997 3.638681
998 6.113550
999 7.832550
Length: 1000, dtype: float64
Conditional Mean uses target alignment¶
When modeling the conditional mean in an AR-X, HAR-X, or LS model, the \(X\) data is target-aligned. This requires that when modeling the mean of y[t], the correct values of \(X\) must appear in x[t]. Mathematically, the \(X\) matrix used when estimating a model should have the structure (using the Python indexing convention of a T-element data set having indices 0, 1, …, T-1):
forecast uses origin alignment¶
Forecasting with \(X\) values aligns them differently. When producing a 1-step-ahead forecast for \(Y_{t+1}\) using information available at time \(t\), the \(X\) values used for this forecast must appear in for t. This is needed since when once wants to produce true out-of-sample forecasts (see below), it must be the case that the final row of x passed forecast must all occur after the final time stamp of the most recent \(Y\) value. Mathematically, the \(X\)
matrix used in forecasting should have the following structure (using Python indexing convention so that a \(T\) observation dataset will have indices 0, 1, …, T-1).
where \(|\mathcal{F}_{s}\) is the time-\(s\) information set.
If you use the same x value in the model when forecasting, you will see different values due to this alignment difference. Naively using the same x values ie equivalent to setting
In general this would not be correct when forecasting, and will always produce forecasts that differ from the conditional mean. In order to recover the conditional mean using the forecast function, it is necessary to shift the \(X\) values by -1, so that once shifted, the x values will have the relationship
Here we shift the \(X\) data by -1 so x[s] is treated as being in the information set for y[s-1]. Also, note that the final forecast is NaN. Conceptually this must be the case because the value of \(X\) at 999 should be ahead of 999 (i.e., at observation 1,000), and we do not have this value.
[18]:
exog_dict = {col: exog[[col]].shift(-1) for col in exog}
fcast = res.forecast(horizon=1, x=exog_dict, start=0)
fcast.mean
[18]:
| h.1 | |
|---|---|
| 0 | 15.403422 |
| 1 | 9.315820 |
| 2 | 9.488624 |
| 3 | 8.559554 |
| 4 | 7.762946 |
| ... | ... |
| 995 | -1.863553 |
| 996 | 3.638681 |
| 997 | 6.113550 |
| 998 | 7.832550 |
| 999 | NaN |
1000 rows × 1 columns
(Nearly) out-of-sample forecasts¶
These “in-sample” forecasts are not really forecasts at all but are just fitted values with a different alignment. If you want real (nearly) out-of-sample forecasts\(\dagger\), it is necessary to replace the actual values of \(X\) with their conditional expectation. This can be done by taking the fitted values from AR(1) models of the \(X\) variables.
\(\dagger\) These are not true out-of-sample since the parameters were estimated using data from that same range of indices where these forecasts target. True out-of-sample requires both using forecast \(X\) values and parameters estimated without the period being forecasted.
[19]:
res0 = ARX(exog["x0"], lags=1).fit()
res1 = ARX(exog["x1"], lags=1).fit()
forecast_x = pd.concat(
[res0.forecast(start=0).mean, res1.forecast(start=0).mean], axis=1
)
forecast_x.columns = ["x0f", "x1f"]
in_samp_forcast_exog = {"x0": forecast_x[["x0f"]], "x1": forecast_x[["x1f"]].shift(-1)}
fcast = res.forecast(horizon=1, x=in_samp_forcast_exog, start=0)
fcast.mean
[19]:
| h.1 | |
|---|---|
| 0 | 15.604500 |
| 1 | 13.437086 |
| 2 | 6.197433 |
| 3 | 7.348452 |
| 4 | 9.613635 |
| ... | ... |
| 995 | -1.959829 |
| 996 | 2.570777 |
| 997 | 5.044351 |
| 998 | 7.095907 |
| 999 | NaN |
1000 rows × 1 columns
True out-of-sample forecasts¶
In order to make a true out-of-sample prediction, we need the expected values of X from the end of the data we have. These can be constructed by forecasting the two \(X\) variables and then passing these values as x to forecast.
[20]:
mod = arch_model(y, x=exog, mean="ARX", lags=1)
res = mod.fit(disp="off")
actual_x_oos = {
"x0": res0.forecast(horizon=10).mean,
"x1": res1.forecast(horizon=10).mean,
}
fcasts = res.forecast(horizon=10, x=actual_x_oos)
fcasts.mean
[20]:
| h.01 | h.02 | h.03 | h.04 | h.05 | h.06 | h.07 | h.08 | h.09 | h.10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 999 | 9.676023 | 9.686183 | 9.416125 | 9.130348 | 8.916961 | 8.789463 | 8.734033 | 8.7303 | 8.759534 | 8.807153 |